背景
如今分布式系统和微服务架构的盛行,一个普通的操作可能在服务端就得由多个服务和数据库实例协同完成的。特别是在互联网金融等一致性要求较高的场景下,多个独立操作之间的一致性问题显得格外棘手。随着业务的快速发展、业务复杂度越来越高,几乎每个公司的系统都会从单体走向分布式,特别是转向微服务架构,随之而来就必然遇到分布式事务这个难题,而分布式事务管理服务正是为了解决这样的问题而诞生。
本篇文章也将分享常见的几个分布式事务的解决方案,也是过去一段时间我在分布式事务学习的一些沉淀。
什么是分布式事务
说到事务大家了解,所有的事务都必须要满足ACID的原则,也就是原子性,一致性,隔离性,持久性。
在以前的单体架构中,往往只有一个服务,这个服务只访问一个数据库,业务比较简单。基于数据库本身的特性就已经能实现ACID了。但是现在我们要研究的微服务,微服务的业务往往比较复杂,一个业务就会跨越多个服务,每个服务都会有自己的数据库或者数据源,这时候如果还靠业务自己的数据库是难以实现整个业务的ACID的。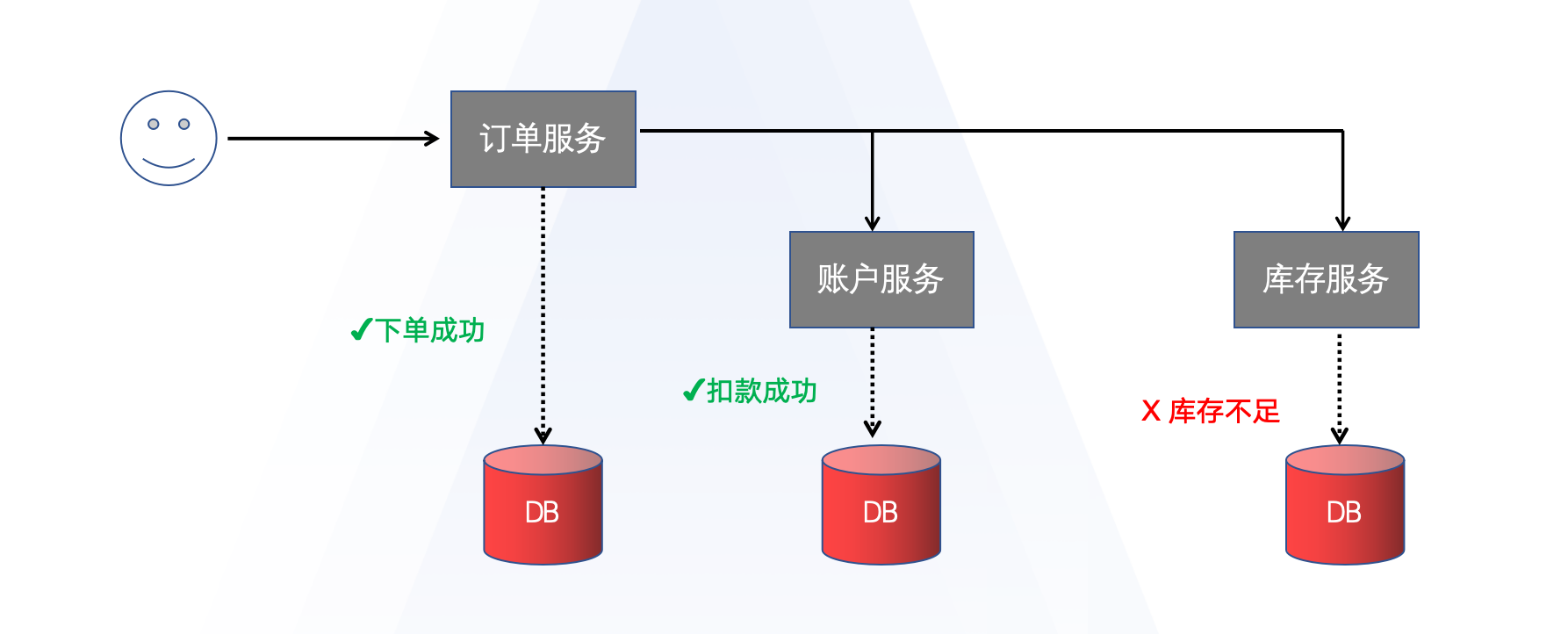
在分布式系统下,一个业务跨越多个服务或数据源,每个服务都有一个本地事务,要保证所有本地事务最终状态一致,这样的事务就是分布式事务。
分布式事务理论基础
解决分布式事务的理论基础主要是两个理论,一个是CAP定理,一个是Base理论
- CAP定理:
2000年,加州大学的计算机科学家 Eric Brewer提出,分布式系统有三个指标,Consistency(一致性),Availability(可用性),Partition tolerance(分区容错性)。但我们都知道在分布式系统中,分区是没有办法避免的,而在发生网络分区的时候,强一致性和可用性只能二选一,这就是CAP定理。

- Base理论
而在实际的场景下,一致性和可用性都非常地重要,两者都不想放弃,而BASE理论则是可以解决这个问题。
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available(基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但在软状态结束后,最终达到一致性
其实BASE理论就是对CAP理论中的C和A的矛盾所做的调和和选择,在CAP理论中我们讲想要达到一致性,那么就要牺牲可用性,但是在BASE里我们说,如果想要达成强一致性,是要牺牲可用性,但不是完全不可用,而是允许损失部分可用性,即保证核心可用。
就比如说在ES集群中,有一个节点发生了故障,我们会将其从集群中剔除,这时候当前节点不可用,但是没关系,一旦它的网络恢复了,我们会重讲将它加入集群之中,重新给它分片,使其重新可用。反过来,如果我们想要达到完整的可用性,在CAP中需要牺牲一致性,但是在BASE理论中,只是临时的不一致,在软状态结束后,我们会使其最终达到一致性。
而在我们分布式事务中,往往包含多个子事务,各个子事务各自执行和提交,结果有些成功,有些失败,这时候大家的状态不一致,但是我们希望事务中的各个子事务状态能够一致,要么大家都成功,要么大家都失败。因此我们可以借鉴CAP定理和BASE理论解决分布式最大的问题是各个子事务的一致性问题。
第一种 解决方案就是基于AP的模式,各个子事务分别执行和提交,允许出现结果不一致,然后采取弥补措施恢复数据即可,实现最终一致。
第二种是基于CP模式,各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务执行过程中,处于弱可用状态。
分布式事务模型
但是不论基于AP还是CP模式,这里都有一个共同点,那就是各个本地事务都需要互相通信,来辨别彼此的通信,但是各个子事务之间怎么进行通信呢?所以它就是需要有一个协调者来帮助分布式事务中的各个子事务进行通信,感知彼次的状态。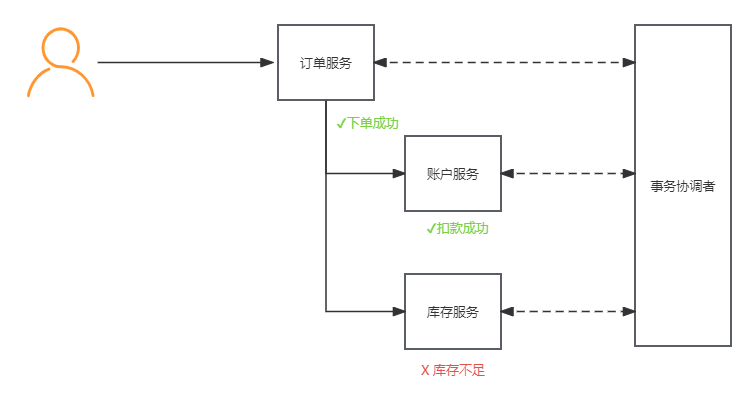
这里的子事务系统称作分支事务,有关联的各个分支事务组合在一起称为全局事务
在分布式事务管理系统中由三个重要的角色组成:
- TC(Transaction Coordinator)-事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚
- TM(Transaction Manager)-事务管理器:定义全局事务的范围,开始全局事务,提交或回滚全局事务
- RM(Resource Manager)-资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚
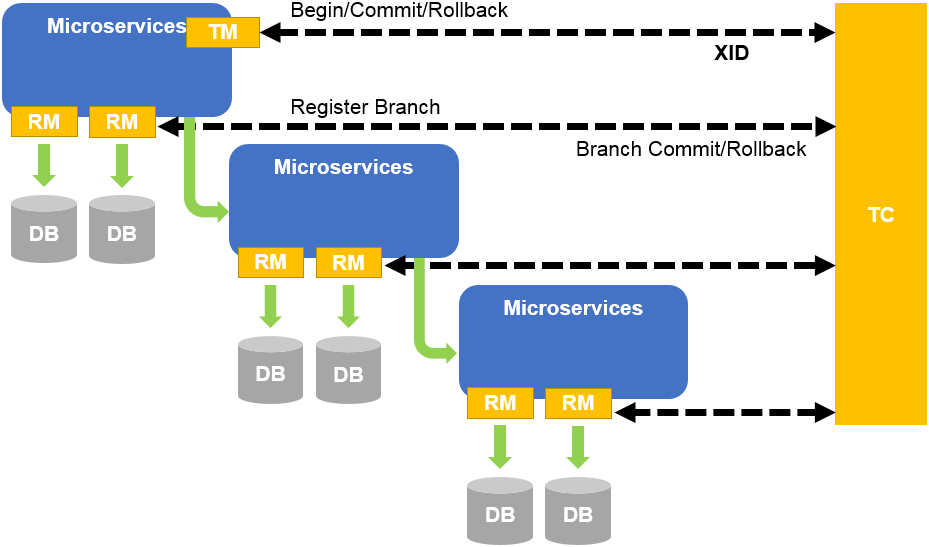
一个典型的事务过程包括:
- TM 向 TC 申请开启(Begin)一个全局事务,全局事务创建成功并生成一个全局唯一的 XID。
- XID 在微服务调用链路的上下文中传播。
- RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖。
- TM 向 TC 发起针对 XID 的全局提交(Commit)或回滚(Rollback)决议。
- TC 调度 XID 下管辖的全部分支事务完成提交(Commit)或回滚(Rollback)请求。
当然这只是GTXS中的事务模型,并不是最终的解决方案。在实际的分布式事务管理系统中会根据业务是要做强一致还是最终一致延伸出了好几种解决方案。比如有XA模式,AT模式,TCC模式,SAGA模式。
分布式事务常见解决方案
XA模式
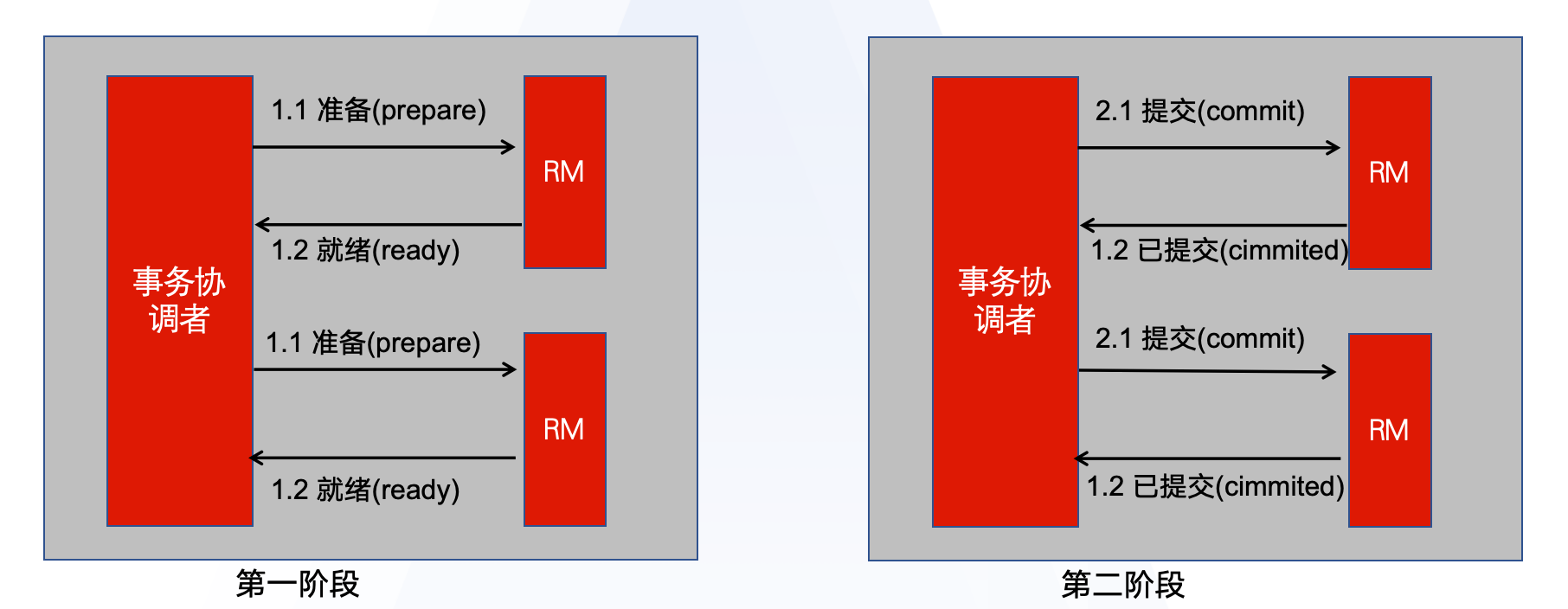
XA规范是X/Open 组织定义的分布式事务处理的标准,那么这个标准叫DTP标准,可以认为是分布式事务领域最早的一个标准。所以几乎所有主流的数据库都对XA规范提供了支持。比如MYSQL ,ORACLE都实现了这种标准,换言之这些数据库内部都已经实现了分布式事务,而采用的模式则是XA模式。这种分布式事务把XA模式定义成了两个阶段。
第一阶段叫做准备阶段,事务协调者在准备阶段会向资源管理者RM发起准备的请求,在以下图片中RM是由事务参与者的SDK组成的,但是在这里RM是由数据库本身实现的,所以在此事务协调者会通知各个微服务的数据库执行自己的sql,但是执行完不要提交,而是把执行执行的结果告诉事务调节者进行就绪,事务协调者会根据各个事务的执行情况判断下一阶段的事情。
如果都成功了则通知各个分支事务的数据库进行提交,否则让他们进行事务的回滚。所以我们看到这种XA模式就是基于数据库本身的特性来实现的分布式事务,因为一阶段并不提交,在二阶段才进行提交或回滚,它们是能够满足事务的ACID的特性的,它是一种强一致性的事务。
XA模式的优势与不足
- 优点
前面我们提到各个分支事务在一阶段的时候只是执行事务而不提交,那么这个事务一直处于运行中的一个状态,那么我们知道事务本身就具备ACID的特性,到了二阶段时候,所有的事务都执行完了再一起提交,所以每个分支事务都具备ACID的能力,而每个事务之间都互相等待,所以整个全局事务都具备ACID的特性。所以这种XA模式具备强一致性的,这是它的第一个优势。那么第二个优势就是说数据库本身就已经实现了分布式事务的能力,我们只是在其基础上做了封装,实现起来也比较简单,在使用的时候是没有代码入侵的,这是它第二个优势
- 缺点
由于分支事务在执行完业务sql的时候并不会进行事务的提交,而是等待TC的过程中会占用数据库锁,如果其他分支事务耗时较长,整个过程中所有的分支事务都处于等待的状态,其他事务都没办法进行资源的访问,造成了资源的浪费,所以它的性能是非常差的,可用性就降低了。第二个缺点,XA模式是依赖于数据库的实现,如果数据库不支持XA的规范,就比如说Redis这种非关系型的数据库,XA模式就没办法实现,这是它的第二个缺点。
AT模式
AT模式同样是分阶段提交的事务模型,不过弥补了XA模型中资源锁定周期过长的缺陷。整体来说它还是这个模型,一开始都是一样的,TM开启全局事务并完成全局事务的注册,然后去调用我们的每个分支,每个RM都到TC进行分支事务的注册,并且执行本地业务SQL,但是此处AT执行完SQl之后会立即提交分支事务,而不是等待其他事务的提交,所以它的性能会优于XA模式。但是为了能够进行分支事务的回滚,RM会拦截SQL的执行并且给数据形成快照undo log,这时一阶段就可以放心大胆地提交,然后将状态报告给TC。第二阶段TM在执行完分支事务的调用之后会通知TC进行全局事务的提交。TC会根据分支事务的状态来判断提交或回滚。此处的提交并不是数据库事务的提交,而是通知各个分支事务RM将undo log 进行删除,并且是异步删除,进一步提高性能。如果存在失败的分支事务,则会通知后各个分支事务进行数据的回滚,一旦回滚成功,也需要将undo log进行删除。这就是二阶段的变化。以上就是AT模式的玩法。
AT模式的优势与不足
优点
AT是基于XA 2PC的模式实现的,针对于木桶效应,通过业务数据提交时自动拦截所有 SQL,将 SQL 对数据修改前、修改后的结果分别保存快照,生成行锁,通过本地事务一起提交到操作的数据源中,相当于自动记录了重做和回滚日志。这样每一个数据源都可以单独提交,然后立刻释放锁和资源。
缺点
提高了吞吐量的同时,破坏了隔离性,会出现脏写的情况(在回滚前数据发生了改变,导致无法逆向SQL来补偿数据)
TCC模式
TCC模式和AT模式相似,每个阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复,需要实现三个方法:
Try:资源的检测和预留
Confirm:完成资源操作业务,要求Try成功 Confirm一定要能成功
Cancel:预留资源释放,可以理解Try的反向操作
SAGA模式
SAGA模式是GTXS提供的长事务解决方案,也分为两个阶段。它在一阶段的时候直接提交本地事务,而在二阶段的过程中如果成功则什么都不做,如果失败则通过编写补偿业务来回滚。聊到这大家可能觉得这和TCC模式也很像,但其实不一样。因为TCC在一阶段并不是提交事务,而是做资源的预留而已,这里一阶段直接提交事务。
而第二阶段也不一样,TCC在第二阶段是对预留资源的扣除或者回滚,而SAGA在第二阶段如果成功则什么事情都不做,如果失败则通过编写补偿方法来回滚事务。
但也因为SAGA模式在第二阶段直接操作的资源本身,所有它也失去了TCC模式中资源的隔离效果,所以SAGA模式中最大的缺点就是没有隔离性,事务与事务之间是可能存在脏写的,所以它是有隔离的安全问题。它的执行流程有下面这张图。它会在第一阶段按照顺序逐个执行分支事务,而一旦在这个事务流程有事务的执行出现了问题,则会反向地去执行补偿逻辑,从而保证整个事务地状态一致性。
它还有一个特点是,它这里地每个分支事务是可以基于事件驱动的,而这种事件有一个好处就是它的吞吐能力会比较强,它不会阻塞和等待,你们可以理解它是一种状态机的机制来实现。但也因此每个分支事务的执行事件不确定,所以它的时效性可能比较差。
这种模型一般比较适用于事务跨度比较大的情况的场景来使用,但是一般SAGA的使用场景是比较少的,一般都是TCC或者FMT模式。
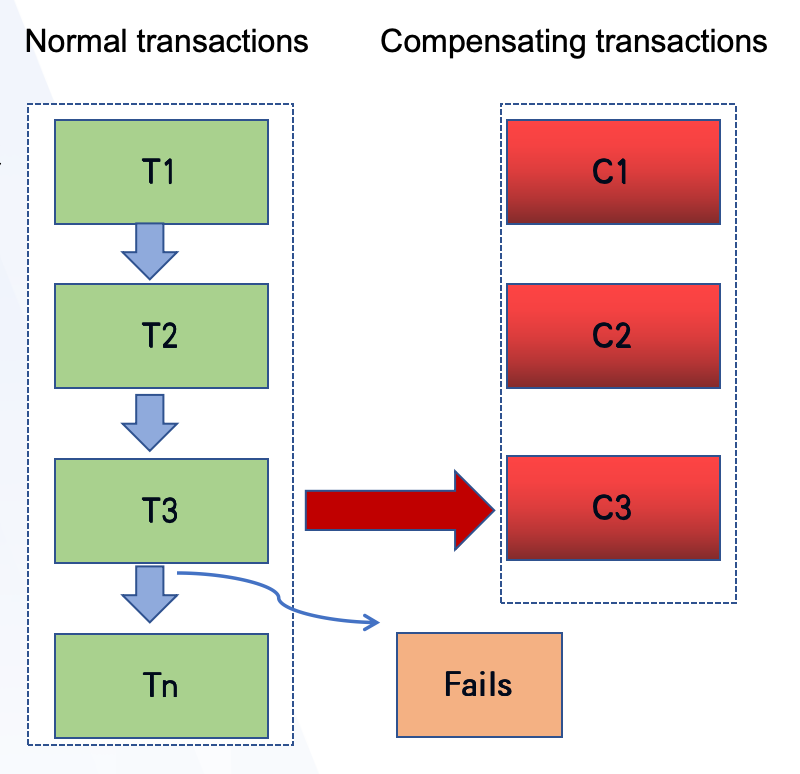
SAGA模式的优势与不足
- 优点
事务参与者可以基于事件驱动实现异步调用,吞吐高
一阶段直接提交事务,无锁,性能好
不用编写TCC中的三个阶段,实现简单
- 缺点:
软状态持续时间不确定,时效性差
没有锁,没有事务隔离,会有脏写
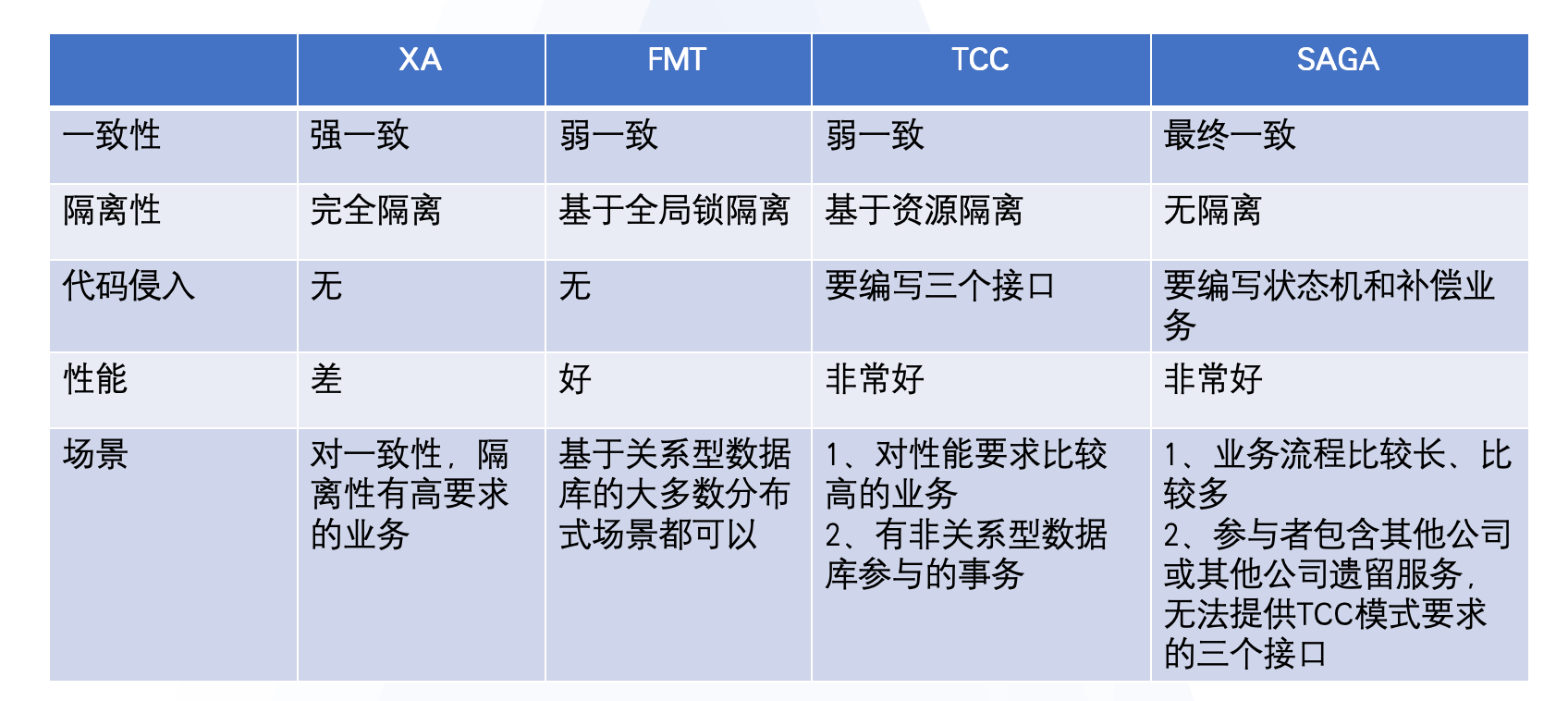
四种模式对比