轻舟网关两地三中心整体技术方案
背景概述
轻舟云原生网关作为轻舟平台核心组件,负责承接集群内外的所有入口流量,并对其进行转发和治理。而两地三中心作为一种容灾能力相对比较完整的架构,有助于提升产品的稳定性,具备业务容灾能力。因此本次方案将实现网关产品的两地三中心能力,并具备区域路由优先和多集群服务发现等产品能力。
需求说明
功能需求
区域路由优先
网关基于区域匹配信息进行流量优先级划分。
多集群服务发现
控制面能够发现多集群中的服务实例。
非功能需求
多集群配置下发
API Plane支持下发配置到多个集群中。
数据一致性保障
通过定时补偿任务达到数据最终一致性的目标
基于K8s Informer缓存资源数据
API Plane通过K8s Informer机制缓存资源数据,避免通过k8s api server全量拉取资源。
目标和非目标
目标:
通过阅读该文档,明白网关两地三中心项目的设计思路及方案,并能通过该方案进行相关落地。
非目标:
阅读人员需要熟悉网关整体架构,主要面向开发和运维人员。
系统指标
功能指标
实现两地三中心多集群部署,保障每个集群的网关代理组件的无状态性。
提供区域路由优先的产品能力,保证流量优先转发到当前集群。
提供多集群服务发现能力,实现多集群服务的统一纳管。
提供多集群配置下发能力,保证多集群网关配置的一致性。
支持灵活部署,资源有限的场景下,可以支持数据面高可用,控制面单集群部署。
性能指标
保证两地三中心部署模式下,流量转发延时和单集群延时保持一致。
多集群下每个网关都可以承接所有流量,QPS理论上可以n倍于单集群网关。
功能架构设计
区域路由优先
两地三中心模式下,可以通过地区(region)、可用区(zone)、集群(cluster)三元组定义网关和业务服务实例的地域信息。
- 地区:代表较大的地理区域,例如杭州。一个地区通常包含许多可用区域。通过node标签mlha.skiff.netease.com/region确定服务的地区。
- 区域:代表一个可用区,例如滨江。一个区域内通常会部署多个集群。通过node标签mlha.skiff.netease.com/zone确定服务的可用区。
- 集群:代表服务所在的K8S集群,通过node标签mlha.skiff.netease.com/cluster确定服务的可用区。
例如:【杭州、滨江、集群A】,【杭州、余杭、集群B】
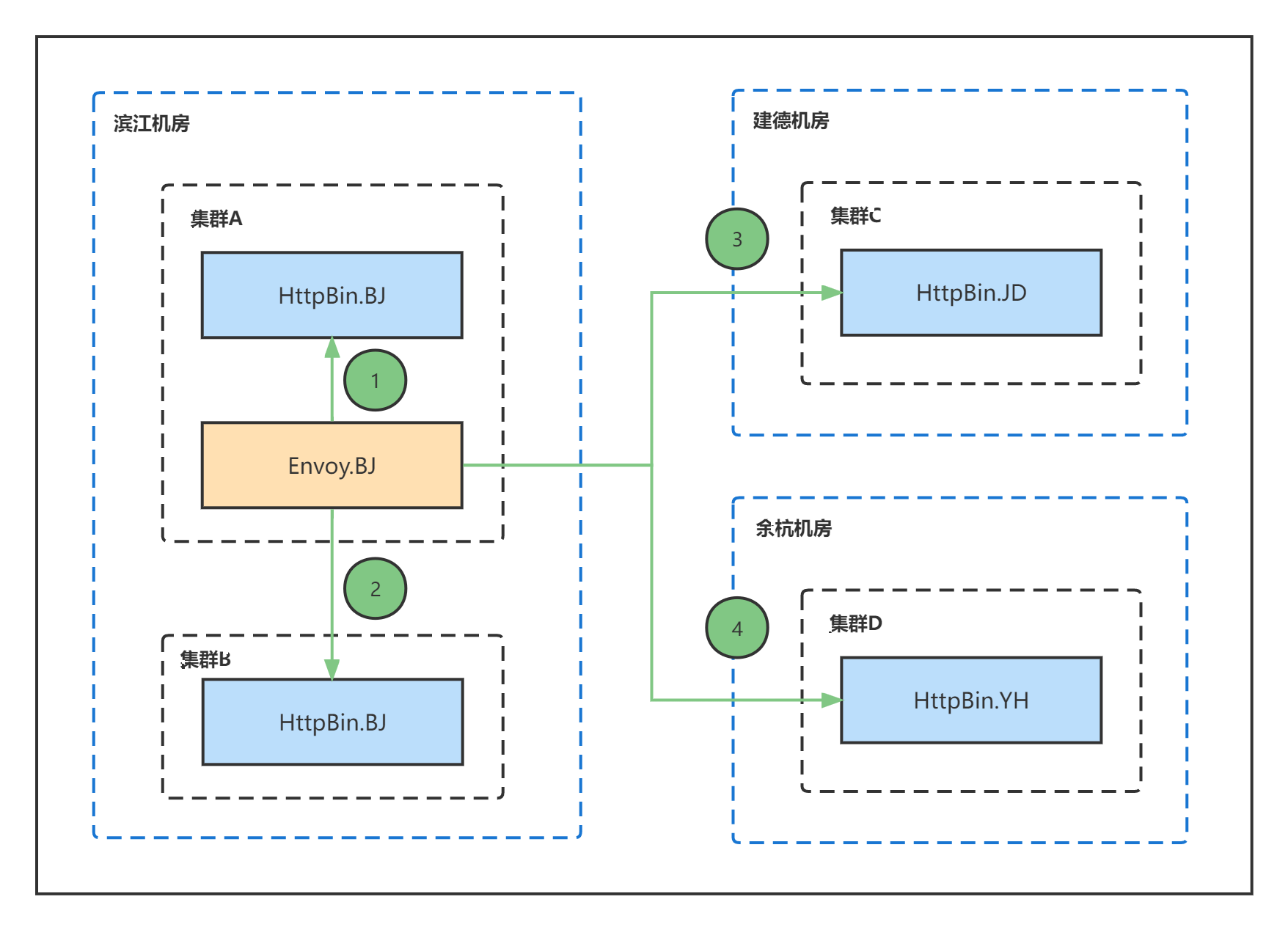
若开启地域区域路由优先功能,网关代理(Envoy)会基于如下规则对流量进行转发:
1.优先将请求转发到当前集群中的服务。
2.若网关所在集群的服务不可用,则将流量转发到当前可用区中其他集群的服务。
3.若网关所在可用区的服务都不可用,则将流量转发到当前区域中其他集群的服务。
4.若网关所在区域的服务都不可用,则将流量转发到其他区域中的服务。
技术架构设计
网关两地三中心方案是在现有网关组件的基础上,通过多集群配置下发与监听、多集群服务发现等技术实现网关集群无状态水平扩展,每个集群都包含完整的网关组件。
整体技术架构
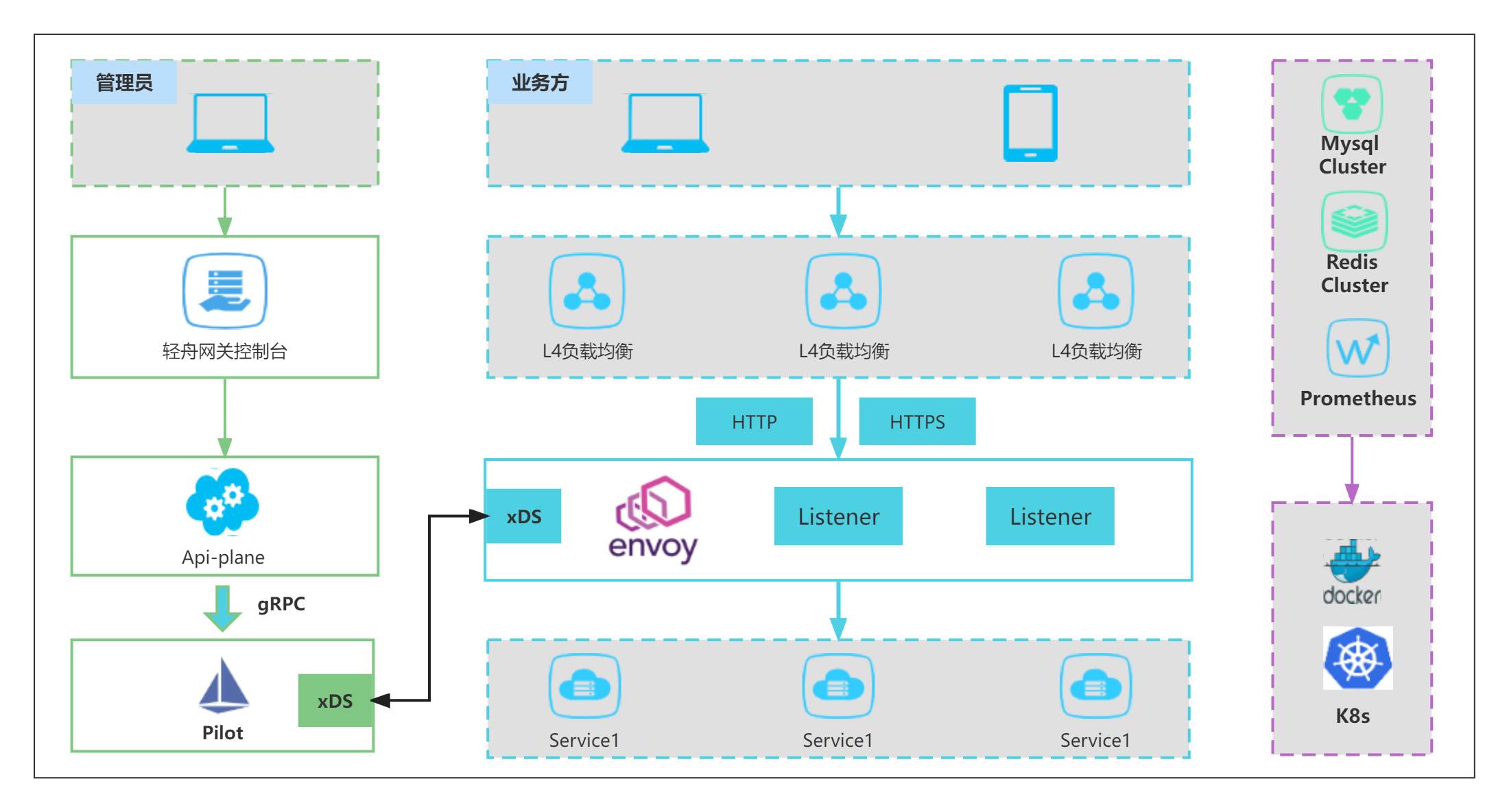
网关的整体架构如图所示,主要可以划分为如下4部分:
控制面组件
控制面组件负责配置管理和服务发现,具体包括如下组件:
Front:前端组件,负责轻舟网关的可视化展示。
GPortal:轻舟网关控制台,和前端组件交互,负责配置管理和可视化。
API Plane:资源管理组件,和K8s api server交互,负责配置资源(CRD)的创建。
Istio Pilot:网关团队基于Istio开源控制面Pilot进行增强,主要负责与数据面Envoy的交互,包括服务以及配置等信息通过xDS协议与数据面进行交互。
Mesh Registry:服务发现组件,通过MCP协议从注册中心获取服务实例,支持的注册中心包括Nacos、Kubernetes、Eureka、Zookeeper。
数据面组件
网关代理组件(Envoy Proxy),负责流量治理和转发,当网关使用集群限流功能时,需要额外部署Rate Limit组件。
多集群架构
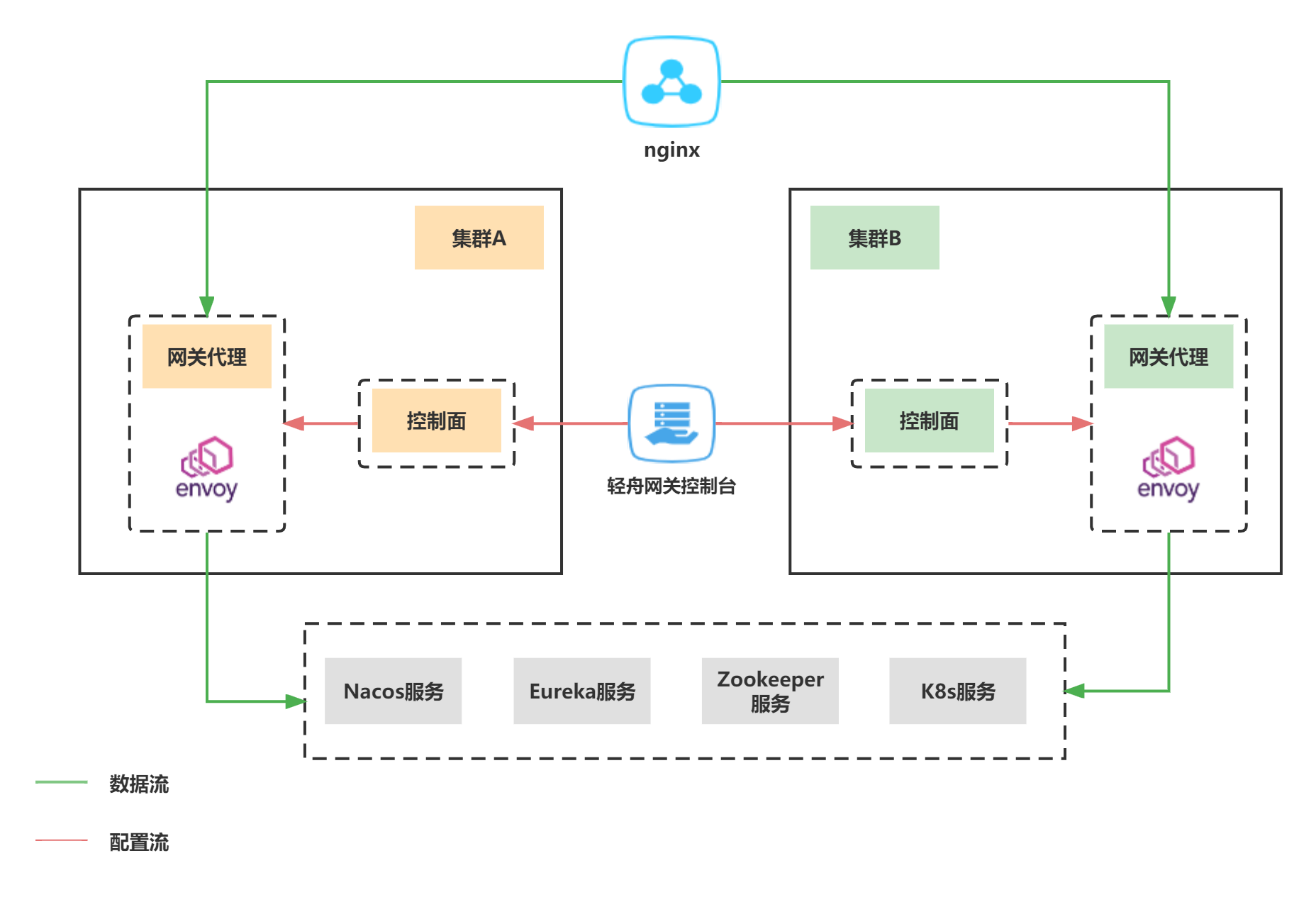
网关多集群水平扩展后如图所示,每个集群都包含完整数据面和控制面组件,其中数据面组件包含完整的服务和配置信息,可以完整承接网关流量,上层通过Nginx进行流量负载均衡。
持久化数据依赖说明
网关依赖的持久化组件如下:
Mysql(强依赖):持久化流量治理相关配置,用于视图管理和资源下发。
Etcd(强依赖):K8s Api Server依赖组件,每个K8s集群都单独维护一个Etcd,用于存储相关Istio配置资源,Istio监听Etcd资源并下发配置给挖宝方法代理Envoy。
Redis(可选):用于缓存和限流插件。
Prometheus(可选):用于指标数据上报和统计。
部署架构设计

网关两地三中心部署方案如上所示,其中区域1为当前提供服务的区域,通过SLB将流量负载均衡到可用区A和B中;区域2为异地区域,区域1中的mysql配置数据会定时同步到可用区C的灾备中间件中。当进行故障切换时,需要执行如下两步骤:
1.同步最新的mysql配置数据到灾备数据库中。
2.基于同步后的灾备数据,全量发布网关资源(服务、路由、插件)。
容灾方案设计
同城单机房故障应对及影响
平台侧
SLB感知机房故障,自动将流量切换到同城可用机房,不会对流量产生影响。
业务侧
部署在本机房中的业务服务将无法接受流量,因此推荐用户将服务分散部署在多个集群中,避免机房故障导致服务实例不可用。
同城双机房故障应对及影响
平台侧
故障期间会导致网关不可用,需要人为切换到灾备机房,切换后需要同步最新数据到灾备数据库中,并进行全量资源发布后可正常提供服务。
业务侧
当前可用区中的服务将不可用,灾备机房中的服务可以正常接受流量。
关键方案设计
多集群读写
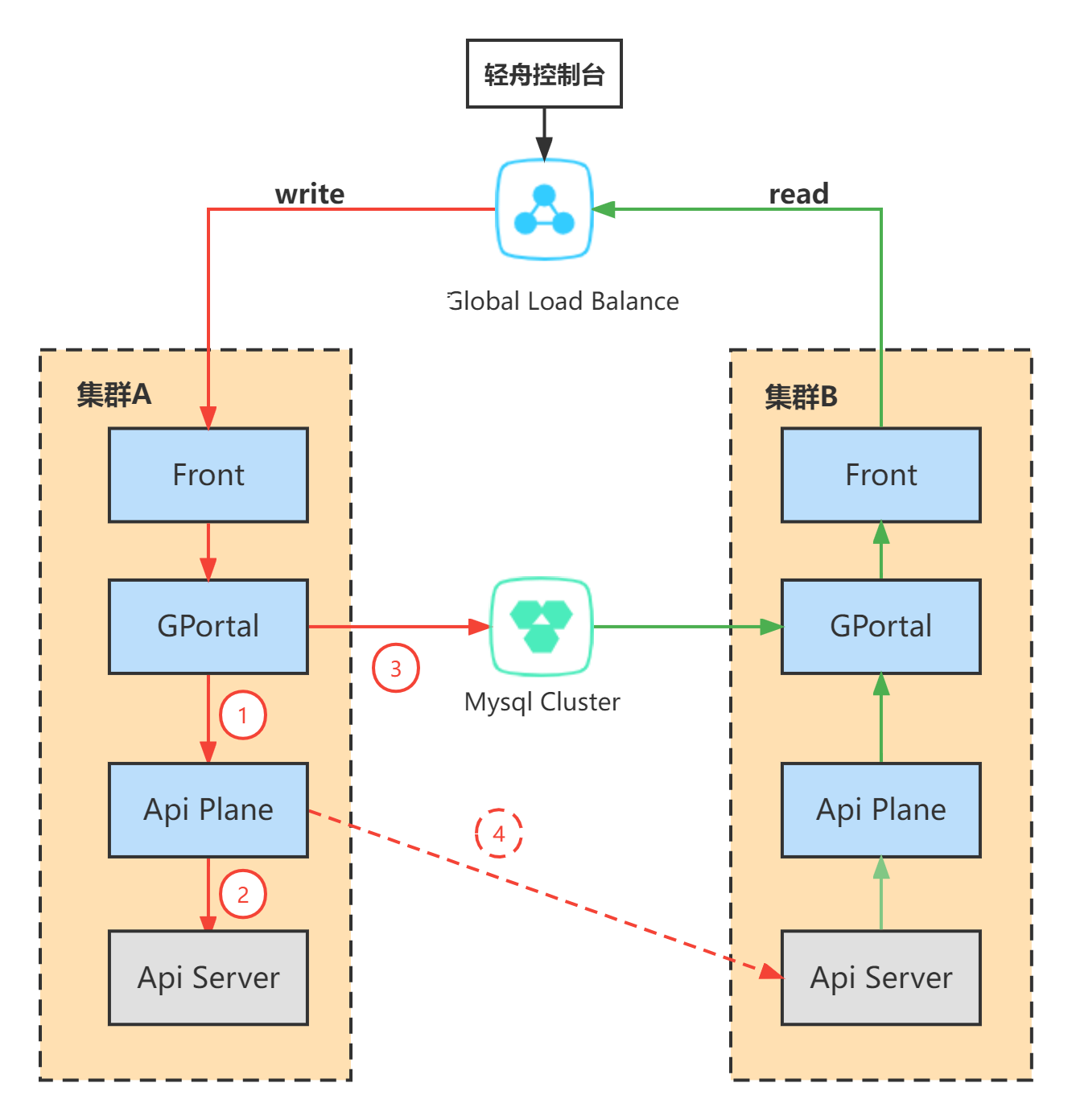
在网关下发配置流程中,GPortal负责落库,API Plane负责下发配置到K8S API Server。在两地三中心场景下,API Plane还需要提供多集群配置下发的能力。在具体实现层面,api plane需要指定主机群和从集群配置,其中主机群为当前集群,从集群为其他集群。
clusters:
master:
k8s-api-server: ""
cert-data: ""
key-data: ""
ca-data: ""
test209:
k8s-api-server: ""
cert-data: ""
key-data: ""
ca-data: ""读操作
对于读操作API Plane只从主集群中读取配置,若主集群crash,会导致pass平台视图展示失败,需要通过Nginx进行切换;
写操作
写操作包含GPortal落库和API Plane多集群配置下发两个操作。本方案优先API Plane下发配置,并且只要主集群配置下发成功,就返回成功,GPortal执行DB操作。对于从集群则通过子线程异步进行更新,若更新失败导致数据不一致,则需要通过定时补偿任务进行修正,保证数据的最终一致性。
定时补偿任务
本方案通过API Plane执行定时补偿任务对数据进行修正。其中每个API Plane组件都会校验本集群中CR和DB数据是否一致,若出现不一致,则以DB数据为准更新本集群CR。针对资源类型的不同,API Plane采用版本号校验和内容校验两种方式。
版本号校验:
通过对比DB中版本号和CR中版本号是否一致来判断配置是否成功下发,优先采用该方式,涉及的资源包括Destination Rule、Virtual Service和GatewayPlugin。
具体步骤:
1.相关表添加版本号标识符version字段,数据创建时初始化为0,之后每次修改都自增。
2.API Plane下发配置时需要带上版本号,映射到资源metadata中的hango.data.version字段。
3.定时触发校验校验任务比较两种的版本号是否一致,若版本号一致,则表明配置正常下发了;否则需要基于DB中的数据进行修正,修正场景如下:
| 场景 | 数据库 | CR | 操作 |
|---|---|---|---|
| 配置未更新 | version=2 | skiff.nsf.data.version=1 | 更新CR |
| 配置未创建 | version=2,enable=true | NULL | 创建CR |
| 禁用相关功能 | enable=false | NULL | 不操作 |
| 数据库更新失败 | version=2 | skiff.nsf.data.version=3 | 更新CR |
| 配置未删除 | NULL | skiff.nsf.data.version=1 | 删除CR |
上述为版本号校验的基本步骤,存在下面三种情况需要特殊处理:
双表映射相同资源
解释:两个表映射到相同资源
场景:
1.apigw_service_proxy和apigw_envoy_health_check_rule映射Destination Rule资源。
2.apigw_route_rule_proxy和apigw_gportal_dubbo_info映射Virtual Service资源。
解决方案:只在主映射表(apigw_service_proxy, apigw_route_rule_proxy)添加版本号,从映射表更新配置时,需要更新主映射表的版本号。
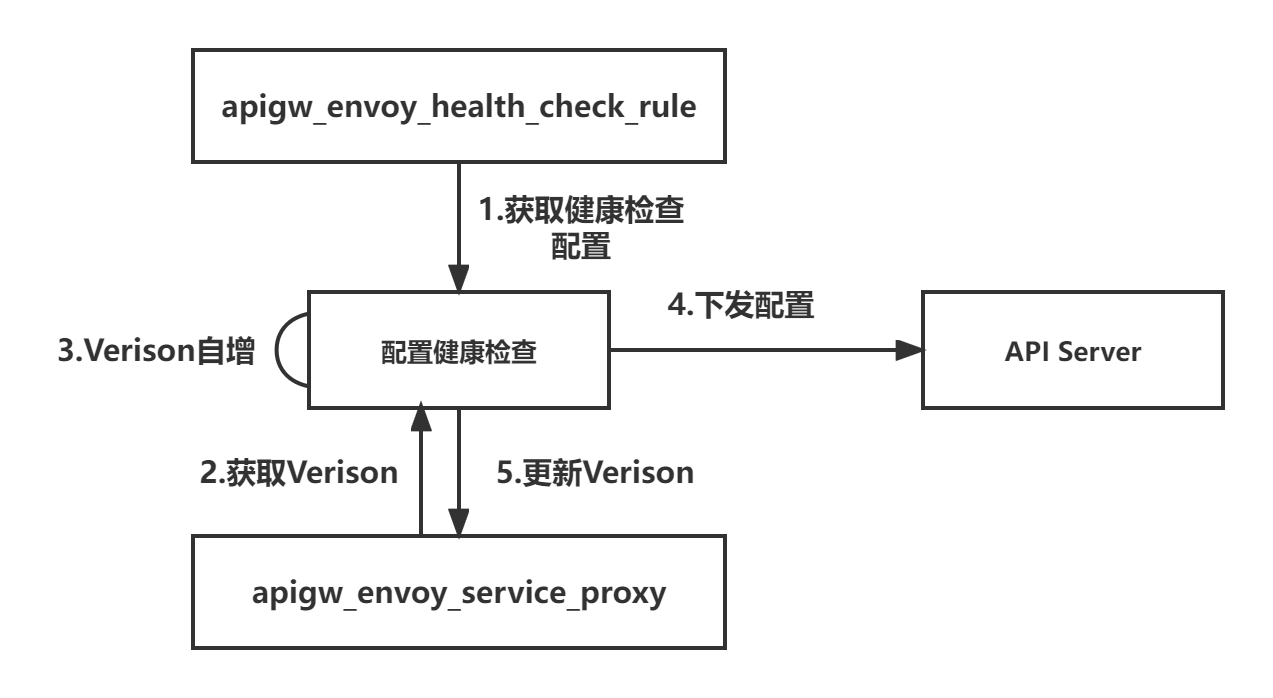
同表多记录映射相同资源
解释:同一个表中的多条记录映射到相同场景
场景:路由级插件apigw_envoy_plugin_binding表中相同路由下的多个插件映射到同一个GatewayPlugin资源
解决方案:多条记录维护相同的版本号,具体步骤如下:
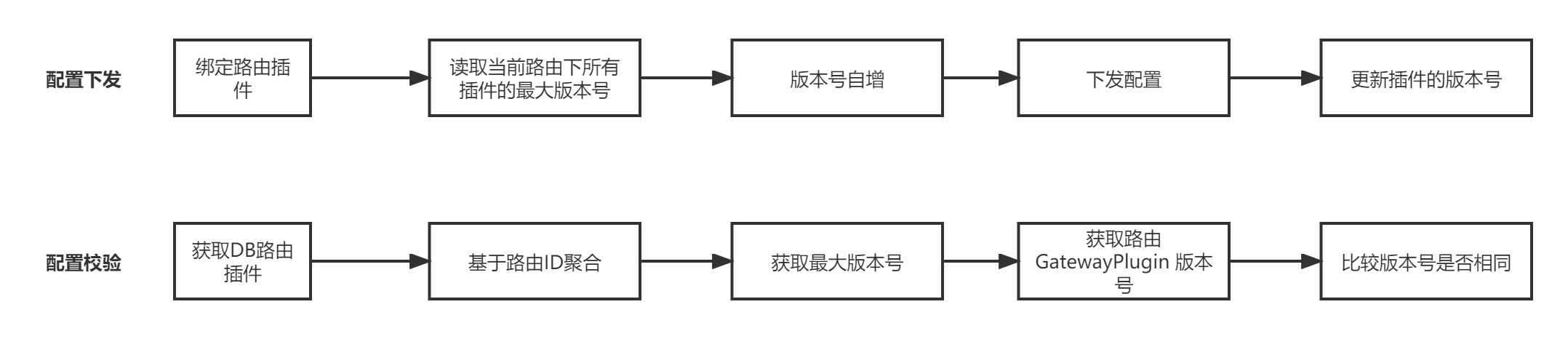
内容校验:
直接比较CR资源和DB中的详细内容,该方式主要应用于内容相对简单的场景,具体指Service Entry资源。该资源只包含静态服务地址信息。
API Plane资源监听
定时补偿任务需要全量拉取K8s 资源进行校验,数据量过大时查询较慢(1w+数据需要查询3分钟),导致api server压力过大,同时导致并发问题影响补偿任务的正确性。为了解决上述问题,本方案通过K8s Informer机制实现资源缓存。
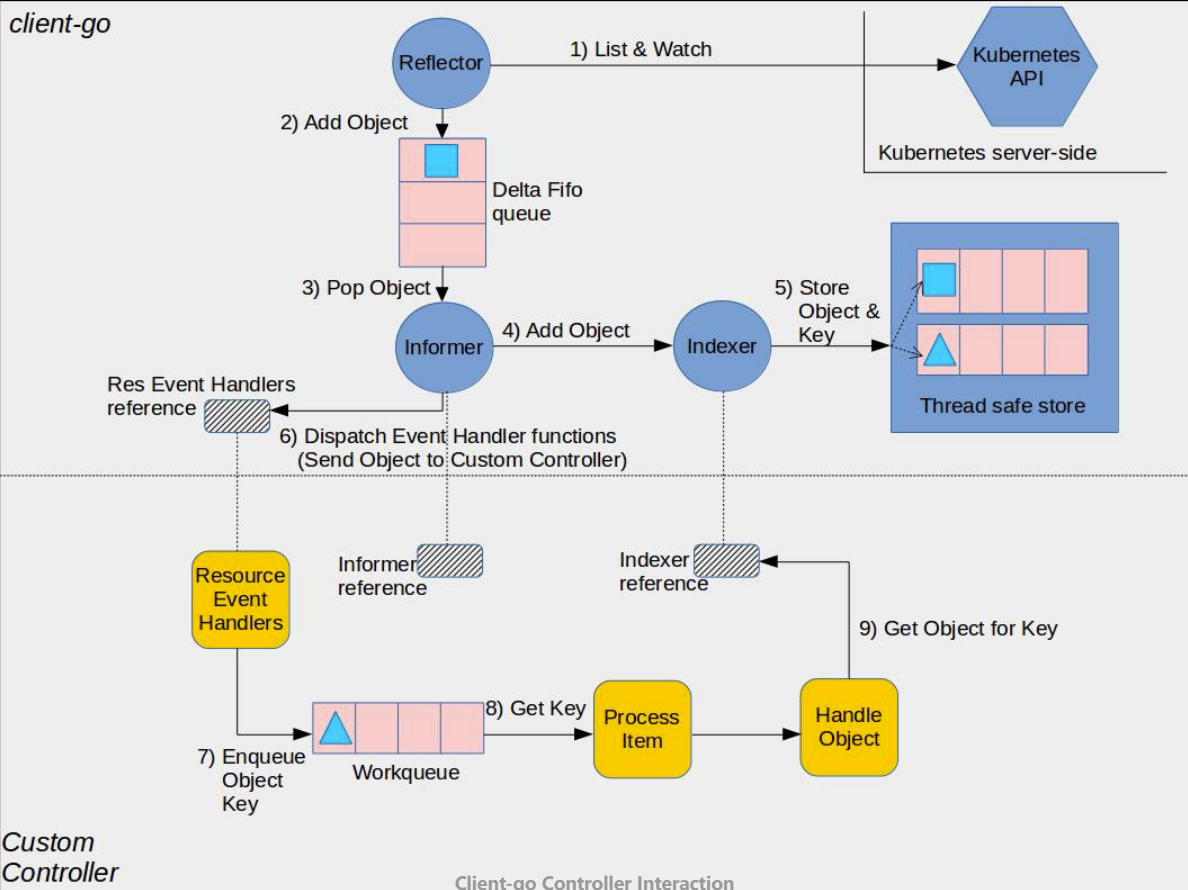
K8s Infomer机制的核心是List/Watch,Api plane 在全量拉取资源时会使用Informer中的Lister()方法,从本地缓存中(store)获取,而非直接请求Kubernetes API。而本地缓存则通过watch机制进行实时更新。具体原理可参考Kubernetes Informer详解 。
Istio多集群服务发现
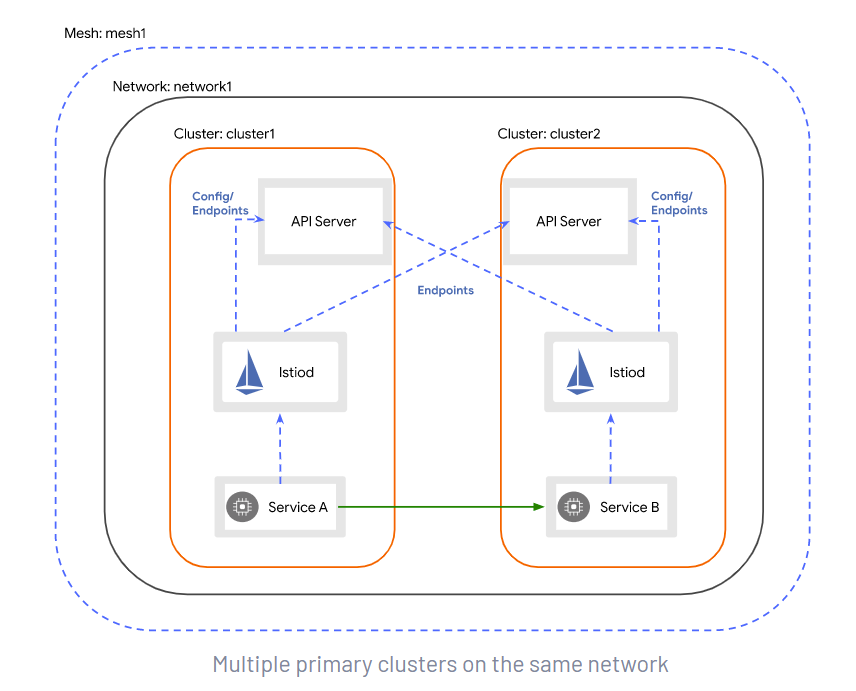
该部分主要基于Istio提供的多主架构部署方案实现,需要保证多集群处于单一的互通网络,任意负载间网络可达。该方案中每个集群中的Istio都会监听所有集群K8s API服务器的服务端点,从而实现获取所有集群中的服务实例。
Mesh Registry也具备多集群监听的能力,实现方式参照Istio,因此不进行额外说明。
监控、告警及运维
无
遗留或待解决问题
无
讨论及更新记录
无



